mirror of
https://github.com/kohya-ss/sd-scripts.git
synced 2026-04-09 06:45:09 +00:00
Update train_README-zh.md
fixed some error
This commit is contained in:
@@ -2,7 +2,8 @@ __由于文档正在更新中,描述可能有错误。__
|
||||
|
||||
# 关于本学习文档,通用描述
|
||||
本库支持模型微调(fine tuning)、DreamBooth、训练LoRA和文本反转(Textual Inversion)(包括[XTI:P+](https://github.com/kohya-ss/sd-scripts/pull/327)
|
||||
)本文档将说明它们共同的学习数据准备方法和选项等。
|
||||
)
|
||||
本文档将说明它们共同的学习数据准备方法和选项等。
|
||||
|
||||
# 概要
|
||||
|
||||
@@ -671,7 +672,7 @@ python finetune\make_captions.py --batch_size 8 ..\train_data
|
||||
|
||||
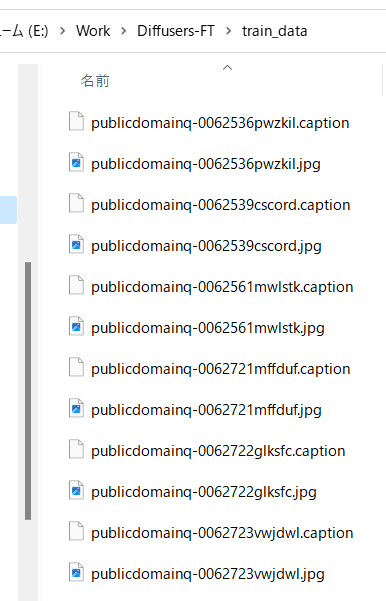
默认情况下,会生成扩展名为 .caption 的字幕文件。
|
||||
|
||||
|
||||

|
||||
|
||||
例如,标题如下:
|
||||
|
||||
@@ -750,7 +751,7 @@ python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
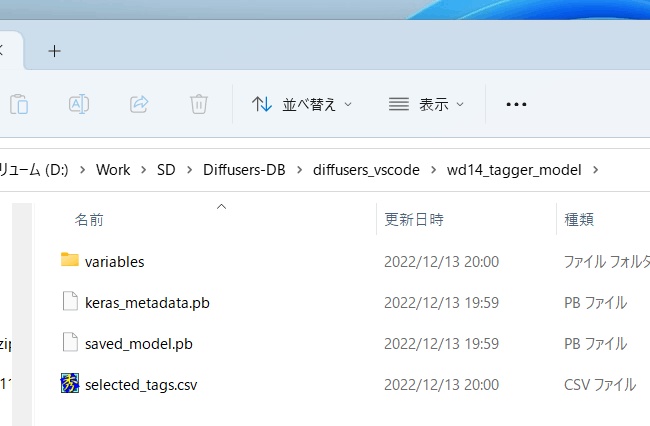
模型文件将在首次启动时自动下载到 wd14_tagger_model 文件夹(文件夹可以在选项中更改)。它将如下所示。
|
||||
|
||||

|
||||
|
||||
在与教师数据图像相同的目录中创建具有相同文件名和扩展名.txt 的标记文件。
|
||||

|
||||
@@ -800,8 +801,8 @@ __* 每次重写 in_json 选项和写入目标并写入单独的元数据文件
|
||||
|
||||
同样,标签也收集在元数据中(如果标签不用于学习,则无需这样做)。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path <教師データフォルダ>
|
||||
--in_json <要读取的元数据文件名> <書き込むメタデータファイル名>
|
||||
python merge_dd_tags_to_metadata.py --full_path <教师资料夹>
|
||||
--in_json <要读取的元数据文件名> <要写入的元数据文件名>
|
||||
```
|
||||
|
||||
同样的目录结构,读取meta_cap.json和写入meta_cap_dd.json时,会是这样的。
|
||||
|
||||
Reference in New Issue
Block a user